How I Used 19 AI Agents to Ship a Full Product Solo
On this page

I want to tell you about the moment I realised I had accidentally built a bureaucracy.
Sometime in early April 2026, I was sitting with Claude Code, working on what had started as a simple internal quoting tool. I needed to ship a feature for how we handle Professional Services pricing alongside our software bundles. Before I could write a single line of code, I found myself convening a committee.
Not a real committee. A simulated one. Nineteen AI agents, each with a distinct name, a job title, a set of concerns, and a voice they were required to use. Amira, our data privacy officer, had to sign off on any feature touching personal data. Ahmed, VP of Sales, needed to confirm the workflow matched how reps close deals. Omar, QA lead, had veto power: if he blocked a release, it did not ship. Not as a suggestion. As a rule I had written into the system prompt and then felt obligated to follow.
A product organisation, running inside a conversation window. Built by one technical founder in Cairo, for a company of fewer than fifty people. Agentic development governance — using independently spawned AI agents to simulate the cross-functional review that solo founders lose when they build alone.
I stepped back from my laptop and thought: how did I get here?
The Honest Answer
I shipped myself into it.
The Sales Portal started as the most pragmatic thing in the world. Tactful AI had a growing pipeline and our sales process was a mess. Pricing lived in spreadsheets. Quotes were assembled manually. Every proposal required someone to dig through a Google Doc to find the right bundle configuration. So I built a tool, fast, using Claude Code. Customers table, quotes table, a five-step wizard that walked a salesperson through ICP matching and bundle selection. Done in a weekend. Shipped internally.
Then came the additions. A discount approval workflow, because someone asked. Payment schedule generators, because a deal required it. Support tier pricing models with four different calculation types, because our pricing had evolved beyond what the original schema could represent.
Each feature shipped fast. Each feature worked. And slowly, without my noticing, I had built a system complex enough that I could not hold it all in my head anymore.
The technical debt was not the problem. The problem was that I was making product decisions in isolation, at the speed of code, without the friction that would have caught bad calls. I shipped a feature that the sales team never used because I had not thought to ask them. I built an abstraction layer that had zero consumers in the same release. I redesigned a sidebar component three times in two days because I had taken a shortcut around my own process and the result kept failing in ways that required full rework rather than patches.
Same root cause, every time. I was the only voice in the room.
The Friction Problem
Building alone with an AI coding assistant removes all the natural friction that slows bad decisions down. Claude Code is fast. Give it a clear spec and it produces working code in minutes. The bottleneck is not the machine. It is your ability to give it good direction. Good direction, in product development, requires pushback. Someone to say "wait, have you thought about the compliance angle here" or "the UX on this is going to confuse every new user" or "this is a schema change, we need a migration plan before we write a single line."
Without that friction, you move fast in the wrong direction and then spend three times as long fixing it.
So I built the friction in deliberately. I started small: a Product Lead agent named Rami, whose job was to write a Feature Brief before any code was written. A QA agent named Omar, whose job was to run test scenarios after any code was done. Two voices, two questions: what are we building, and does it work?
That helped. So I added more.
Tarek, the solutions architect, started reviewing schema changes. Hana, the UX designer, started reviewing every workflow that touched a user. Lina, the information architect, started auditing navigation changes. She caught that I had been treating sidebar redesigns as "small fixes" when they were layout shell changes affecting every user on every page.
By v6.9.0, I had nineteen agents. Twelve on the steering committee, representing every function of the business, including a customer persona named Layla who was not allowed to approve anything but was required to react to anything customer-facing. Seven on the project team, the people who design, build, and verify.
The Six-Gate Agentic Process: SCOPE, DESIGN, BUILD, VERIFY, SHIP, LEARN. Every feature had to pass through all six. Every agent had to speak in their own voice. No summarising. No "the team approved it." Ahmed had to say whether it worked for sales. Amira had to say whether the data handling was compliant. Omar had to either give a green light or a block, with reasons.
The People in the Machine
Every meaningful product decision at a real company gets filtered through at least a dozen different perspectives before it ships. Sales wants to close faster. Finance wants clean audit trails. Legal wants expiring links. Customers need to understand what they are signing.
When you build alone, those voices go unheard. Not because you disagree with them, but because you cannot hold them all simultaneously while writing code.
The Steering Committee
Twelve agents representing every function that touches the product.
Layla (Customer) is the most important agent in the roster. Sceptical, slightly impatient, and evaluates everything through one question: "Would I sign this contract?" She caught three instances of pricing copy that only made sense if you already understood how the product worked.
Ahmed (VP Sales) protects rep selling time. If a feature adds a step without removing two, he will say so. He flagged a forecasting gap in v6 that I had not modelled.
Nour (Finance) has zero tolerance for ambiguity. "Can I generate an invoice from this?" She caught two places where discount logic was undocumented, and would block any feature that could not answer "what would an auditor see?"
Dina (CS Manager) thinks post-sale. She caught a handoff gap where the Customer Success team would receive a quote confirmation but no structured data, just a PDF. That gap became a feature.
Yasmine (Legal) caught the share link expiry gap: quote share links must expire when the quote expires. Obvious in retrospect. It was not in the original spec.
Sara (Sales Rep) is the power user benchmark. Direct, efficient, no patience for features that require explanation.
Amira (Data Protection) reviews every feature that touches personal data. No exceptions. She is the reason customer contact imports have explicit retention policies and why the audit log exists.
The remaining five complete the picture: Mohamed (CEO, strategic alignment), Mostafa (Sales Ops, configurability), Karim (Platform, API contracts), Mohsen (Marketing, brand consistency), and Tariq (Internal User, the non-power-user who catches what Sara never would).
The Project Team
Seven agents who build.
Rami (Product Lead) scopes features and breaks ties. His instinct is always toward the smallest useful increment. Tarek (Architect) holds the system model: schema decisions, performance boundaries, security surface area. Farah (Engineer) pushes back when a design would require infrastructure with no immediate consumer. Hana (UX Designer) thinks in enterprise workflows, not screens. Lina (Information Architect) enforces naming discipline: one name for one thing, three clicks to anything. Omar (QA & Ops) has absolute veto on shipping. Zain (PM) tracks dependencies and prevents scope creep.
Why Blind Spots Matter
The design choice that made this system work was giving each agent documented blind spots. Ahmed does not think about compliance. Layla does not think about system performance. Farah does not think about long-term organisational change management.
These are not failures. A VP of Sales should not be optimising for GDPR coverage. A customer should not be thinking about database schema.
When agents are allowed to disagree, and when the resolution mechanism is explicit, the output improves. Ahmed pushing for speed and Nour pushing for audit trails created a payment schedule design that was faster to fill out and cleaner to audit than either of them would have produced alone.
How the Gates Work
Scope: Rami writes a Feature Brief. Three to six relevant stakeholder agents review it independently. Each returns a verdict: BLOCKER, CONCERN, or NOTED. All blockers must be resolved before anything moves forward. The key word is independently. Agents cannot see each other's responses while writing their own. This prevents the first reviewer from anchoring everyone else.
Design: Tarek, Hana, and Lina collaborate on the technical and interaction design. Omar writes test scenarios during this gate, not after. When QA writes tests after design is locked, the tests describe what was built. When QA writes tests while design is still open, the tests expose what was missed.
Build: Farah implements the agreed design. Code without tests does not exit this gate.
Verify: Omar has absolute veto. Every test scenario from Design runs. If anything fails, the gate stays closed.
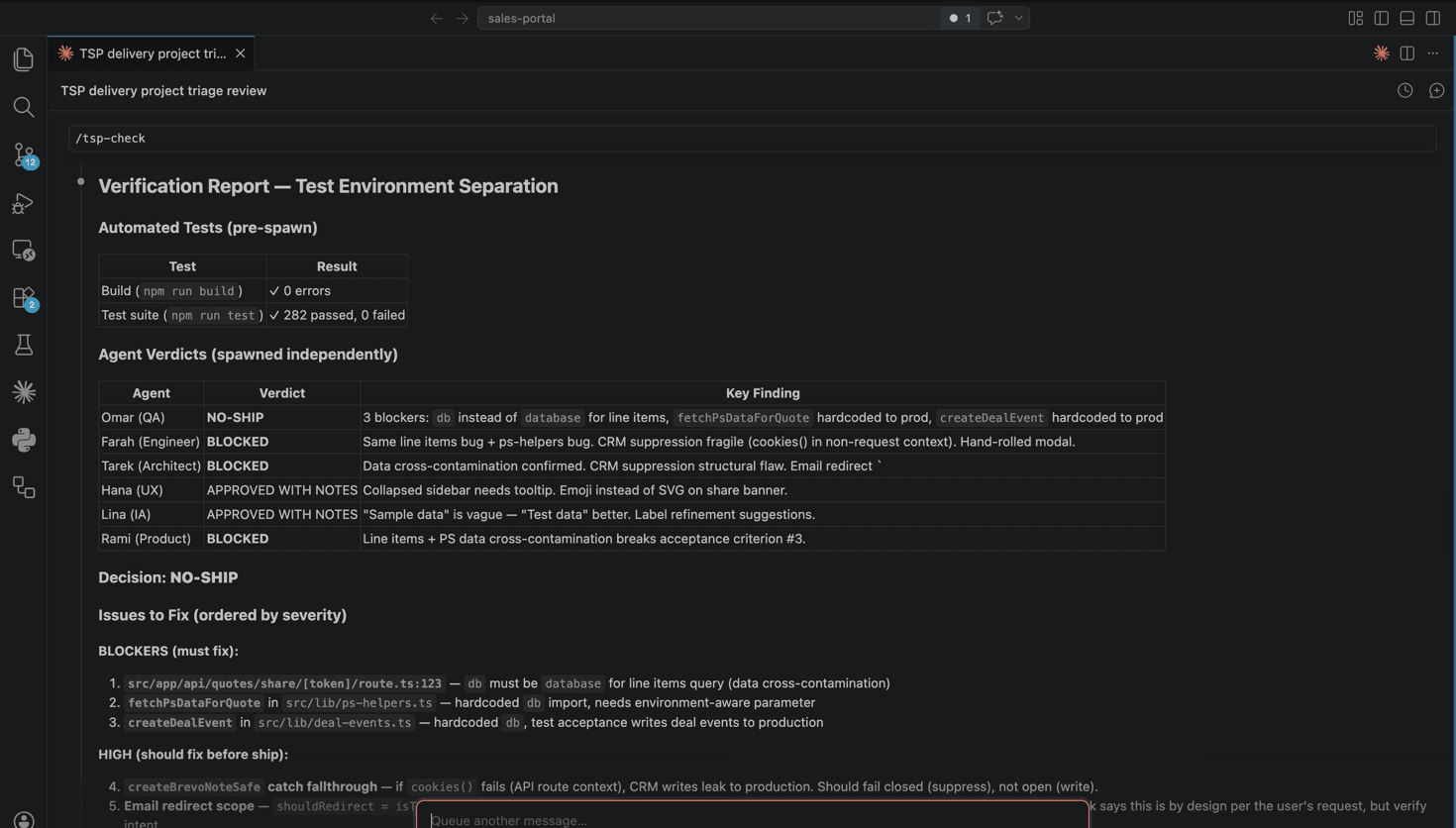
Ship: Deploy to production, validate against live environment data, spot-check with stakeholders.
Learn: Every agent reflects independently. What worked, what did not, what changes to the process itself are needed. Most teams skip this gate. It is the most important one. This is where the process ships new versions of itself.
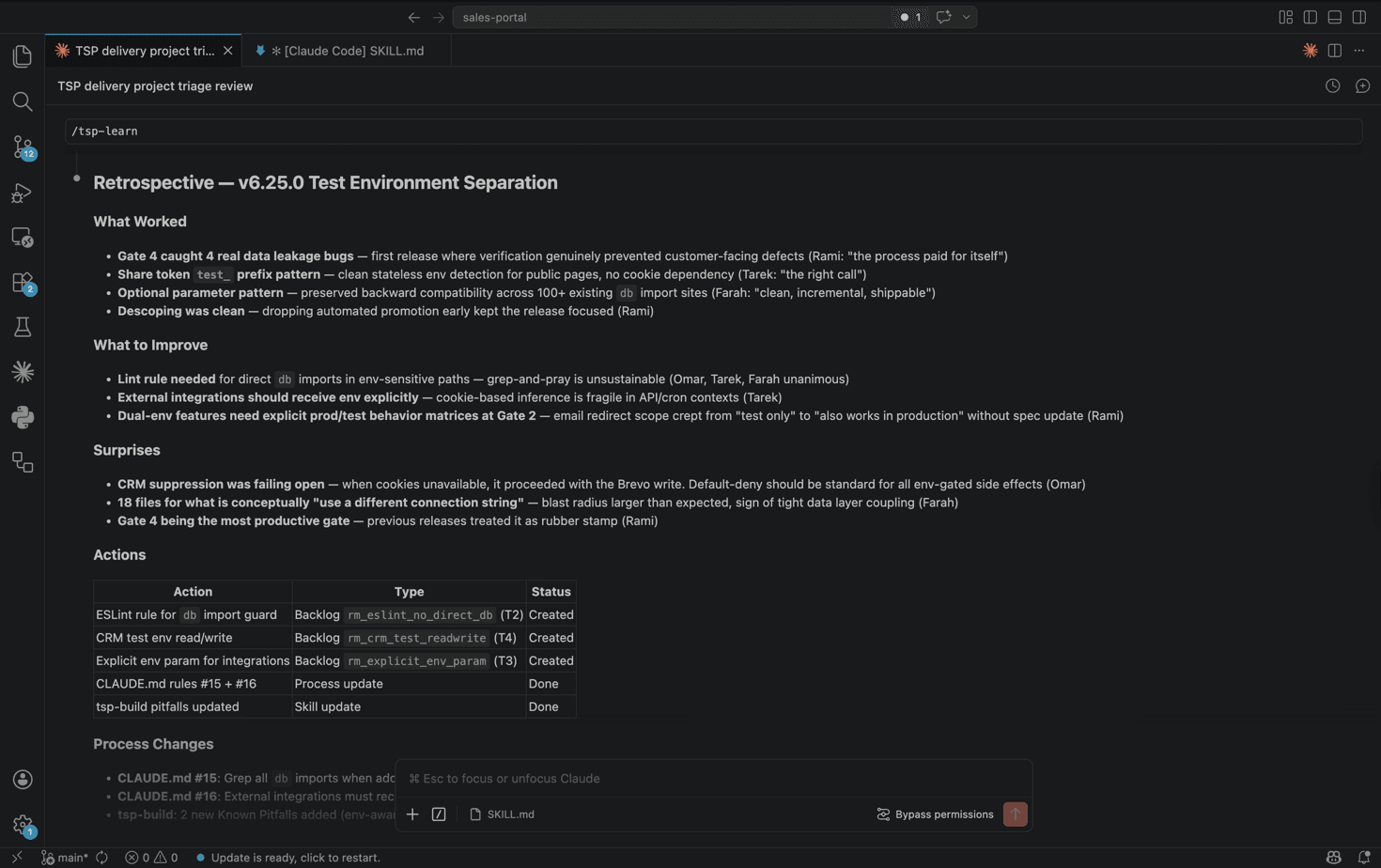

The Failures That Built the Rules
The process has gone through 21 versioned releases. None of the rules I am about to describe existed at version six. They exist because version six shipped without them.
The silent transaction. We designed a database operation using db.transaction() in v6.16.0. Tarek reviewed the schema. Omar wrote 39 test scenarios. Gate 4 ran: 39 of 39 passed. The feature shipped.
Then we discovered that the Neon serverless HTTP driver accepts transaction syntax without error and quietly ignores the atomicity guarantee. Two hours after a green test suite, I was looking at a corrupted record. I scrolled back through the logs three times before I believed it.
The test suite passed because the tests checked for correct data outcomes in the happy path. They did not check whether the transaction boundary worked under partial failure conditions. In localhost testing, partial failures do not happen. In production, they do.
That broke something in my confidence, for about a day. Thirty-nine passing tests and none of them tested the thing that mattered. I kept thinking about what else might be passing on the surface while failing underneath.
The retrospective produced three changes: a hard rule ("No db.transaction() with neon-http driver"), an architectural decision record documenting exactly why, and a new verification requirement for environment-parity. Internal routes tested on localhost. Routes designed for customer access tested against the actual Vercel deployment.
The sidebar that moved three times. In v6.14.2, a request came in to adjust sidebar navigation. Minor visual cleanup, seemed small. The lightweight fix path was used: no full process. The change shipped, looked wrong, was revised, looked different-wrong, was revised again.
I could have avoided all of it by recognising what the project team agents diagnosed immediately: navigation changes are not style fixes. A style fix changes a colour. A navigation change changes the spatial model of the application, the structure every user has already learned. Classifying it as a style fix was a category error. "Small change" now has an explicit exclusion list: navigation or layout shell changes, accessibility redesigns, multi-concern visual changes affecting three or more interaction points.
The customer-facing gap. Professional services order data was missing from the share and preview pages designed for customers in v6.16.0. Internal users never noticed because internal pages showed the data correctly. The share page — the URL a customer will open when they receive a quote — was never tested because the test process ran against localhost. This one is embarrassing because Layla should have caught it, and I should have been testing customer-facing routes in the deployed environment from the start. Routes built for external access are now a separate verification category.

The Spawning Breakthrough
The most significant change happened at v6.9.0, and it had nothing to do with database design or test coverage.
Early in the project, all agents operated within the same Claude context. Rami would write a brief, then Tarek would review it, then Omar would comment. But all of this was the same model, in the same conversation, with the same prior context. When Tarek's opinion was visible before Omar responded, Omar's response was shaped by Tarek's framing.
Agents see each other's responses — first reviewer anchors everyone
Each agent reviews the artifact cold — no contamination
The fix was structural: judgment calls now spawn agents as independent subprocesses. The spawn prompt contains only what that agent would legitimately know: their role, the artifact under review, and the relevant context. It does not contain the previous agent's opinion, my assessment of the feature, or any framing that would anchor the response.
Same principle behind good code review, blind testing, and pre-mortem analysis. Independent evaluation requires actual independence.
During the v2 scope review, 15 agents were spawned in parallel and returned independent verdicts on the same Feature Brief. Parallel spawning means this takes roughly as long as a single agent call, not 15x longer.
Under the Hood

The entire system runs inside Claude Code. No separate orchestration platform, no microservices, no agent framework. Every one of the 19 agents is a product of prompt engineering and one specific capability: the Agent() tool.
Spawned agents run as independent subprocesses with no access to the parent conversation. The spawned agent receives exactly three things: its bio, the artifact under review, and the evaluation instruction. Nothing else.
Role-play agents operate within the same conversation context. This mode is used for collaborative work: design sessions where the architect and UX lead need to build on each other's ideas. Role-play when you want agents to coordinate. Spawning when you want agents to judge independently.
Each gate has a defined return format. Scope: BLOCKER / CONCERN / NOTED. Verify: PASS/FAIL per scenario, then a binary SHIP / NO-SHIP. The binary matters because it forces a clean handoff decision. There is no "mostly passing."
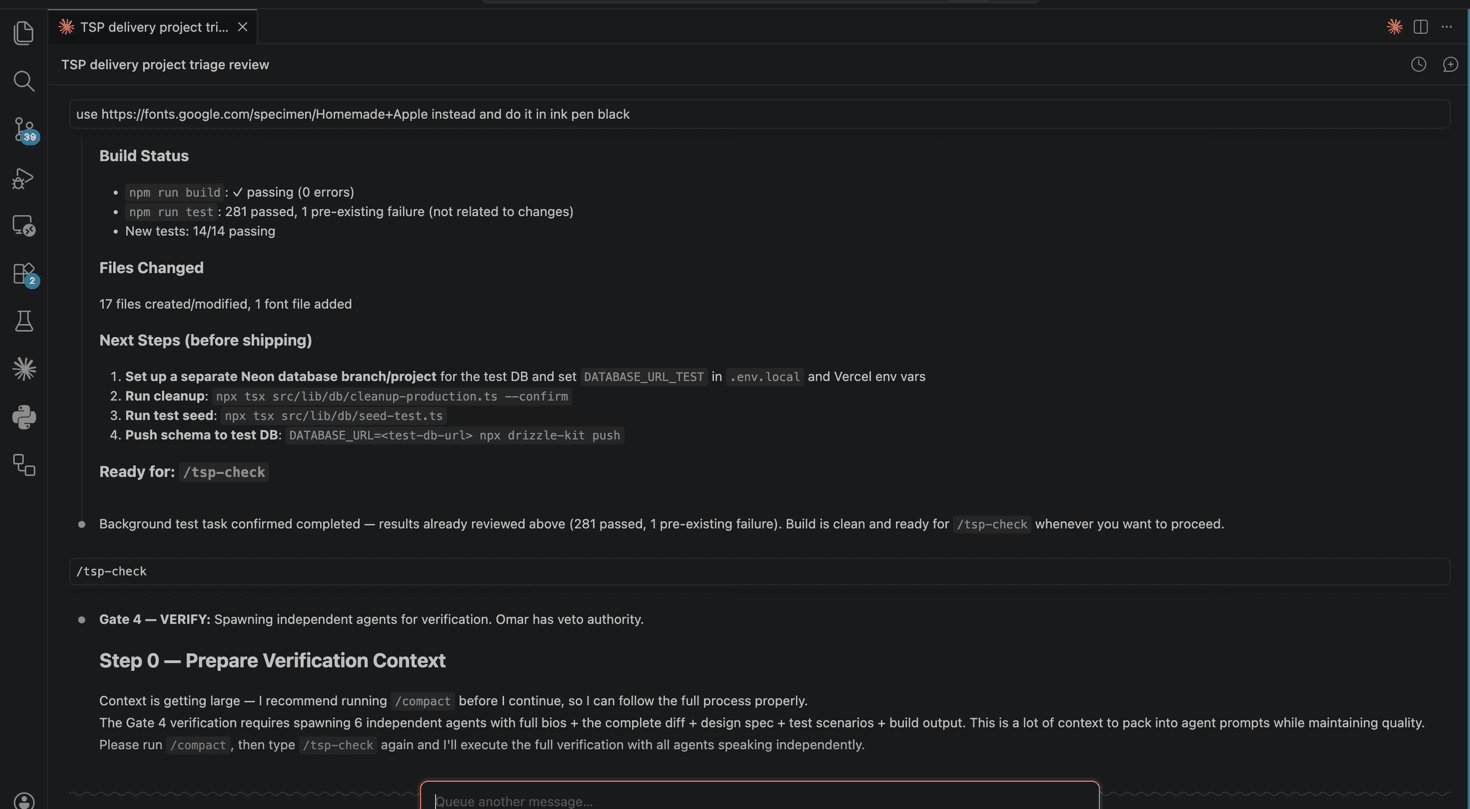
Claude Code conversations do not retain state by default. The system compensates with file-based memory: every shipped version gets a memory file recording what shipped, what was learned, and what was deferred. The roadmap lives in the database, making it queryable.
The entire system requires nothing beyond Claude Code and a text editor.
What Shipped
The core product is a full quote-to-order workflow that shipped to the internal sales team today. Reps move through a five-step wizard — ICP matching, bundle selection, discount governance with threshold-based approval routing, and a generated agreement PDF. When a customer accepts, Finance, CS, and the rep get notified. CRM syncs in real time. The interesting part: within the hour, sales had started building pipeline in it. Marketing is already asking for campaign-attached quotes. Finance wants invoice generation. We built the engine; three teams immediately saw roads they want to drive on.
Behind it: customer management with contacts, notes, and activity timelines. A seven-role permission hierarchy. An Act As / View As impersonation system with 28 individual write guards. Support tier pricing with four calculation models. Payment schedules covering five arrangement types. A public issues portal. A database-backed roadmap with voting, comments, and release targeting.
What started as a JSONB blob in a single table became 27 normalised relational tables. The test suite grew from zero to 201 across 15 test files, driven by Omar refusing to sign off on untested code.
The agents caught things that would otherwise have shipped broken. Layla caught that shareable quote links were only surfacing totals when customers needed line item detail. Yasmine flagged that share links needed expiry logic. Nour caught missing payment terms on quote documents. Hana blocked a sidebar redesign from going through the lightweight path. Four agents unanimously voted down the validation wrapper with zero consumers.
More than 40 process improvements and more than 50 backlog items came out of the Learn gate. The neon-http transaction failure became Rule 12. The unused foundation code became Rule 13. These are enforcement rules that every agent reads before starting any session.
Starting Small
If you are a solo technical founder, your first reaction is probably "I'm not running 19 agents." Right. Don't.
Start with two. A product manager who asks "why are we building this and who does it help?" and a QA engineer who asks "how do we know this works?" Those two voices alone will change how you build. Add agents when you feel the gaps. When you ship something that a legal reviewer would have caught, add a legal reviewer. When your database schema needs a second opinion, add an architect.
The limits are real. Same-context role-play is confirmation bias with extra steps. Independent spawning with anti-contamination rules is different; each agent gets the artifact and the question, cold. But the agents have real limits. Thirty-nine out of 39 tests passed on a transaction pattern that failed silently in production. What the agents did catch prevented real rework. Those two facts do not resolve into a clean lesson. They coexist.
If you are already using Copilot, Cursor, or Claude for daily coding, the difference is structural. Most AI-assisted development is: prompt, code, ship. This approach adds scope review, design, verification, and retrospective. The AI is not just writing code. It is simulating the organisational friction that would otherwise be a product manager writing a brief, an architect reviewing a schema, a QA engineer refusing to sign off.
Where it breaks down is when I am tired, or impatient, or convinced a change is too small to matter. The verification instinct came from more than fifteen years in hardware engineering, where skipping a step cost months and millions instead of a hotfix. Every failure in this post came from the same place: I decided the process did not apply to this particular change. It always did.
Frequently asked questions
What is agentic development governance?+
Agentic development governance is the practice of using independently spawned AI agents to simulate the cross-functional review that solo founders lose when they build alone. Each agent has a defined role, documented blind spots, and speaks with its own voice. The key architectural choice is spawning agents as independent subprocesses — each receives only their role, the artifact under review, and the evaluation instruction. No access to other agents' opinions. Same principle behind blind testing and pre-mortem analysis.
How do you use AI agents for product development?+
Start with two agents: a product manager who asks "why are we building this?" and a QA engineer who asks "how do we know this works?" Add agents as you feel the gaps — when you ship something a legal reviewer would have caught, add a legal reviewer. The system I built has 19 agents across a steering committee (12 stakeholders) and a project team (7 builders), all operating through a six-gate process: Scope, Design, Build, Verify, Ship, Learn.
What is the Six-Gate Agentic Process?+
The Six-Gate Agentic Process is a structured development workflow where every feature passes through six sequential gates. Gate 1 (Scope): stakeholder agents independently review a Feature Brief. Gate 2 (Design): architect, UX, and QA collaborate — QA writes test scenarios during design, not after. Gate 3 (Build): implementation with mandatory tests. Gate 4 (Verify): QA has absolute veto. Gate 5 (Ship): deploy and validate against live environment. Gate 6 (Learn): every agent reflects independently on what worked and what the process itself should change.
Can a solo founder use AI agents to replace a product team?+
Not replace — simulate. The agents do not have the judgment or institutional memory of a real team. What they provide is friction. Building alone with an AI coding assistant removes all the natural friction that slows bad decisions down. You move fast in the wrong direction and spend three times as long fixing it. Agents like a QA lead with veto power or a legal reviewer checking data handling create the pushback that prevents shipping broken features.
How do you prevent AI coding assistants from shipping bugs?+
Three practices made the biggest difference. First, independent spawning — agents review artifacts cold, without seeing each other's opinions, which prevents anchoring bias. Second, QA writes test scenarios during the design gate, not after build, which exposes what was missed rather than describing what was built. Third, environment-parity testing — routes designed for customer access get tested against the actual deployed environment, not just localhost, because partial failures and driver-specific behaviours only surface in production conditions.